[ad_1]
Generative AI algorithms use chance to develop visuals from sounds
Last yr the Net acquired its 1st flavor of picture-creating artificial intelligence. All of a sudden, technological innovation that had at the time been offered only to specialists was available to any individual with a world wide web connection. The enthusiasm reveals no symptoms of abating, and AI-created illustrations or photos have received a big photography competitiveness, made the title credits of a tv sequence and tricked individuals into believing the pope stepped out in a trendy puffer coat. Nonetheless critics have observed how education the algorithms on present is effective could perhaps infringe on copyright, and working with them could put artists’ employment in jeopardy. Generative AI also dangers supercharging faux information: the pope coat was enjoyable, but a created photograph supposedly demonstrating an assault on the Pentagon briefly impressed a dip in the stock industry.
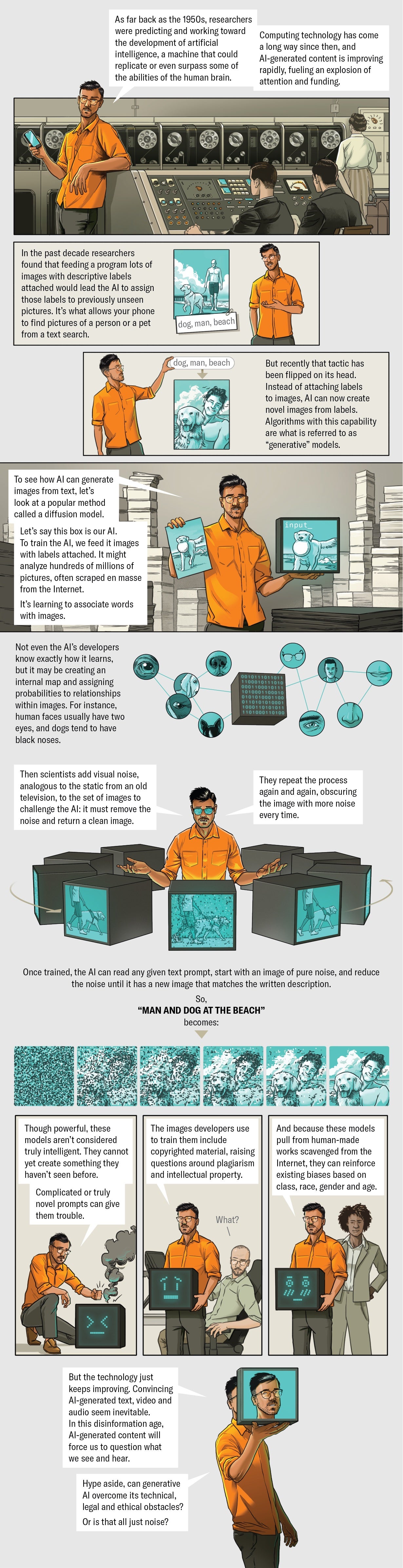
How did plans these as DALL-E 2, Midjourney and Secure Diffusion get to be so superior all at as soon as? Though AI has been in improvement for decades, the most popular of modern graphic generators use a method called a diffusion product, which is reasonably new on the AI scene. Here is how it is effective:


This post was at first revealed with the title “How AI Generates Visuals from Text” in Scientific American 329, 3, 66-67 (Oct 2023)
doi:10.1038/scientificamerican1023-66
ABOUT THE Creator(S)

[ad_2]
Supply url

